
参考:
https://blog.csdn.net/qq_16992475/article/details/139633631
https://blog.csdn.net/zk673820543/article/details/106579809/
记得修改配置,增加rewriteBatchedStatements=true
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://xxx:3306/xxx?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8&rewriteBatchedStatements=true
username: xxx
password: xxx推荐方式
第三种方案,使用sqlSessionFactory实现批量插入(推荐)
@Resource
private SqlSessionFactory sqlSessionFactory;
// 关闭session的自动提交
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
try {
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
list.stream().forEach(user -> userMapper.saveInfo(user));
// 提交数据
sqlSession.commit();
} catch (Exception e) {
sqlSession.rollback();
} finally {
sqlSession.close();
}优势:这种方式可以说是集第一种和第二种方式的优点于一身,既可以提高运行效率,又可以保证大数据量时执行成功,大数据量时推荐使用这种方式。
其他方式
批量修改方案
第一种 for
<!-- 批量更新第一种方法,通过接收传进来的参数list进行循环着组装sql -->
<update id="updateBatch" parameterType="java.util.List">
<foreach collection="list" item="item" index="index" open="" close="" separator=";">
update people
<set>
<if test="item.firstName != null">
first_name = #{item.firstName,jdbcType=VARCHAR},
</if>
<if test="item.lastName != null">
last_name = #{item.lastName,jdbcType=VARCHAR},
</if>
</set>
where id = #{item.id,jdbcType=BIGINT}
</foreach>
</update>第二种 case when
<!-- 批量更新第二种方法,通过 case when语句变相的进行批量更新 -->
<update id="updateBatch2" parameterType="java.util.List">
update people
<trim prefix="set" suffixOverrides=",">
<trim prefix="first_name = case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.firstName!=null">
when id=#{i.id} then #{i.firstName}
</if>
</foreach>
</trim>
<trim prefix="last_name = case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.lastName!=null">
when id=#{i.id} then #{i.lastName}
</if>
</foreach>
</trim>
</trim>
where id in
<foreach collection="list" index="index" item="item" separator="," open="(" close=")">
#{item.id,jdbcType=BIGINT}
</foreach>
</update>第三种 replace into
<!-- 批量更新第三种方法,通过 replace into -->
<update id="updateBatch3" parameterType="java.util.List">
replace into people
(id,first_name,last_name) values
<foreach collection="list" index="index" item="item" separator=",">
(#{item.id},
#{item.firstName},
#{item.lastName})
</foreach>
</update>第四种 ON DUPLICATE KEY UPDATE
<!-- 批量更新第四种方法,通过 duplicate key update -->
<update id="updateBatch4" parameterType="java.util.List">
insert into people
(id,first_name,last_name) values
<foreach collection="list" index="index" item="item" separator=",">
(#{item.id},
#{item.firstName},
#{item.lastName})
</foreach>
ON DUPLICATE KEY UPDATE
id=values(id),first_name=values(first_name),last_name=values(last_name)
</update>
效率比较
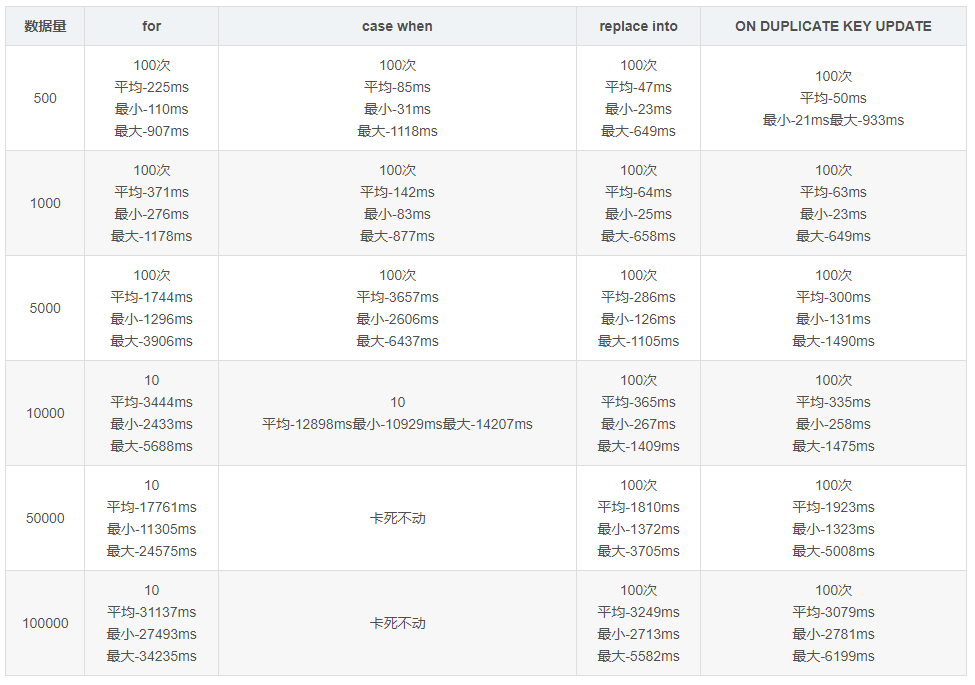
总结
sql语句for循环效率其实相当高的,因为它仅仅有一个循环体,只不过最后update语句比较多,量大了就有可能造成sql阻塞。
case when虽然最后只会有一条更新语句,但是xml中的循环体有点多,每一个case when 都要循环一遍list集合,所以大批量拼sql的时候会比较慢,所以效率问题严重。使用的时候建议分批插入。
duplicate key update可以看出来是最快的,但是一般大公司都禁用,公司一般都禁止使用replace into和INSERT INTO … ON DUPLICATE KEY UPDATE,这种sql有可能会造成数据丢失和主从上表的自增id值不一致。而且用这个更新时,记得一定要加上id,而且values()括号里面放的是数据库字段,不是java对象的属性字段

